基于Java8翻译
基础
入门
Java技术简介和安装Java开发软件并使用它创建简单程序的课程。
学习Java语言
面向对象的编程概念教您面向对象的编程背后的核心概念:对象,消息,类和继承。 本课最后向您展示这些概念如何转换为代码。 如果您已经熟悉面向对象的编程,请随时跳过本课程。
语言基础描述了语言的传统功能,包括变量,数组,数据类型,运算符和控制流。
类和对象描述了如何编写从中创建对象的类,以及如何创建和使用对象。
注解是元数据的一种形式,为编译器提供信息。 本课描述了在程序中的何处以及如何有效使用注释。
接口和继承描述了接口-它们是什么,为什么要编写一个接口以及如何编写一个接口。 本节还描述了可以从另一个类派生一个类的方法。 也就是说,子类如何可以从超类继承字段和方法。 您将了解所有类都派生自Object类,以及如何修改子类从超类继承的方法。
Numbers和Strings本课程描述如何使用数字和字符串对象。本课程还向您展示如何格式化数据以输出。
泛型是Java编程语言的强大功能。 它们提高了代码的类型安全性,使您在编译时可以检测到更多错误。
包是Java编程语言的一项功能,可帮助您组织和构造类及其之间的关系。
面向对象编程概念
如果您以前从未使用过面向对象的编程语言,则需要学习一些基本概念,然后才能开始编写任何代码。本课将向您介绍对象,类,继承,接口和包。每个讨论都集中在这些概念如何与现实世界相关的同时,同时提供对Java编程语言语法的介绍。
什么是对象?
对象是具有相关状态和行为的软件包。软件对象通常用于建模您在日常生活中发现的现实世界对象。本课说明了对象中状态和行为的表示方式,介绍了数据封装的概念,并说明了以这种方式设计软件的好处。
什么是类?
类是从中创建对象的蓝图或原型。本节定义了一个模型,用于对实际对象的状态和行为进行建模。它特意侧重于基础知识,展示了即使是简单的类也可以如何清晰地对状态和行为进行建模。
什么是继承?
继承为组织和构造软件提供了强大而自然的机制。本节说明类如何从其超类继承状态和行为,并说明如何使用Java编程语言提供的简单语法从另一个类派生一个类。
什么是接口?
接口是类与外界之间的契约。当一个类实现一个接口时,它承诺提供该接口发布的行为。本节定义了一个简单的接口,并说明了实现该接口的任何类的必要更改。
什么是包?
包是用于以逻辑方式组织类和接口的名称空间。将您的代码放入程序包使大型软件项目更易于管理。本节说明了这样做的用处,并向您介绍Java平台提供的应用程序编程接口(API)。
问题与练习:面向对象的编程概念
使用本节中提出的问题和练习来测试您对对象,类,继承,接口和包的理解。
什么是对象
对象是理解面向对象技术的关键。现在环顾四周,您会发现许多真实物体的示例:您的狗,书桌,电视机,自行车。
现实世界中的对象共有两个特征:它们都具有状态和行为。狗具有状态(名称,颜色,品种,饥饿)和行为(吠叫,抓捕,摇尾巴)。自行车还具有状态(当前档位,当前踏板节奏,当前速度)和行为(换档,改变踏板节奏,施加制动)。识别现实世界对象的状态和行为是从面向对象编程的角度出发思考的一种好方法。
现在花一分钟时间观察您附近区域中的真实对象。对于您看到的每个对象,问自己两个问题:“该对象可能处于什么状态?”和“此对象可能执行什么行为?”。确保写下您的观察结果。在执行操作时,您会注意到现实世界中对象的复杂性各不相同。您的台式机灯可能只有两种可能的状态(打开和关闭)和两种可能的行为(打开,关闭),但是您的台式收音机可能具有其他状态(打开,关闭,当前音量,当前电台)和行为(打开) ,关闭,增加音量,减少音量,搜索,扫描和调整)。您可能还会注意到,某些对象也将包含其他对象。这些真实的观察结果都转化为面向对象编程的世界。
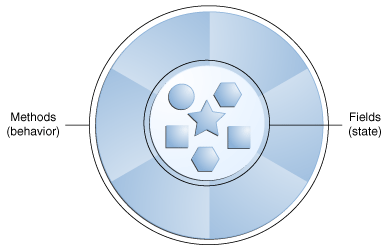
软件对象在概念上与现实世界中的对象相似:它们也由状态和相关行为组成。 对象将其状态存储在字段中(某些编程语言中的变量),并通过方法(某些编程语言中的函数)公开其行为。 方法在对象的内部状态上运行,并用作对象间通信的主要机制。 隐藏内部状态并要求通过对象的方法执行所有交互被称为数据封装-面向对象编程的基本原理。
考虑一辆自行车,例如:
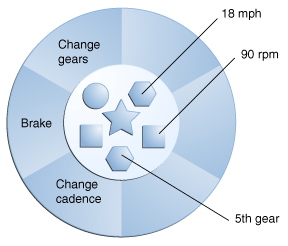
通过归因于状态(当前速度,当前踏板踏频和当前档位)并提供更改状态的方法,对象可以控制外部世界如何使用它。例如,如果自行车只有6档,则更改齿轮的方法可能会拒绝任何小于1或大于6的值。
将代码捆绑到单个软件对象中可带来许多好处,包括:
- 模块化:可以独立于其他对象的源代码编写和维护对象的源代码。创建对象后,可以轻松地在系统内部传递对象。
- 信息隐藏:通过仅与对象的方法进行交互,其内部实现的细节仍对外界隐藏。
- 代码重用:如果某个对象已经存在(也许由其他软件开发人员编写),则可以在程序中使用该对象。这使专家可以实现/测试/调试特定于任务的复杂对象,然后您可以信任它们以自己的代码运行。
- 可插拔性和调试简便性:如果发现某个特定对象有问题,则只需将其从应用程序中删除,然后插入另一个对象作为替换对象即可。这类似于解决现实世界中的机械问题。如果螺栓断裂,请更换,而不是整个机器。
什么是类
在现实世界中,您经常会发现许多同一种个体。 可能还有成千上万的其他自行车,都具有相同的品牌和型号。 每辆自行车都是根据相同的设计图制造的,因此包含相同的组件。 用面向对象的术语来说,我们说您的自行车是称为自行车的一类对象的实例。 类是从中创建单个对象的蓝图。
以下Bicycle类是自行车的一种可能实现:
1 | class Bicycle { |
Java编程语言的语法对您来说似乎很新,但是此类的设计是基于先前对自行车对象的讨论。 节奏,速度和齿轮字段表示对象的状态,方法(changeCadence,changeGear,speedUp等)定义了对象与外界的交互。
您可能已经注意到Bicycle类不包含main方法。 那是因为它不是一个完整的应用程序。 它只是应用程序中可能使用的自行车的蓝图。 创建和使用新的Bicycle对象的职责属于应用程序中的其他一些类。
这是一个BicycleDemo类,它创建两个单独的Bicycle对象并调用它们的方法:
1 | class BicycleDemo { |
此测试的输出显示两辆自行车的结束踏板节奏,速度和齿轮:
1 | cadence:50 speed:10 gear:2 |
什么是继承
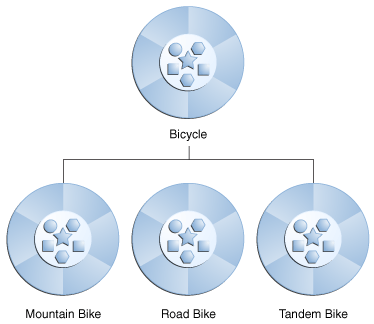
不同种类的对象通常彼此之间有一定数量的共同点。 例如,山地车,公路车和双人自行车都具有自行车的特征(当前速度,当前踏板节奏,当前档位)。 然而,每个自行车还定义了使其与众不同的其他功能:双人自行车有两个座位和两组车把; 公路自行车有下降的车把; 一些山地自行车带有附加的链环,从而降低了齿轮比。
面向对象的编程允许类从其他类继承常用的状态和行为。 在此示例中,Bicycle现在成为MountainBike,RoadBike和TandemBike的超类。 在Java编程语言中,每个类都可以具有一个直接超类,并且每个超类都具有无限数量的子类的潜力:
创建子类的语法很简单。 在类声明的开头,使用extends关键字,后跟要从其继承的类的名称:
1 | class MountainBike extends Bicycle { |
这为MountainBike提供了与Bicycle相同的字段和方法,但允许其代码仅专注于使其独特的功能。 这使子类的代码易于阅读。 但是,您必须注意正确记录每个超类定义的状态和行为,因为该代码不会出现在每个子类的源文件中。
什么是接口
如您所知,对象通过其公开的方法定义了它们与外界的交互。 方法形成对象与外界的接口; 例如,电视机正面的按钮是您与塑料外壳另一侧的电线之间的接口。 您按下“电源”按钮可以打开和关闭电视。
在最常见的形式中,接口是一组具有空主体的相关方法。 如果将自行车的行为指定为接口,则可能如下所示:
1 | interface Bicycle { |
要实现此接口,您的类的名称将更改(更改为特定品牌的自行车,例如ACMEBicycle),然后在类声明中使用Implements关键字:
1 | class ACMEBicycle implements Bicycle { |
实现接口可以使类对其承诺提供的行为更加正式。 接口在类和外部世界之间形成契约,并且该契约在编译时由编译器强制执行。 如果您的类声称要实现一个接口,则在成功编译该类之前,该接口定义的所有方法都必须出现在其源代码中。
注意:要实际编译
ACMEBicycle类,您需要将public关键字添加到已实现的接口方法的开头。 稍后,您将在有关类和对象,接口和继承的课程中了解造成这种情况的原因。
什么是包
程序包是一个命名空间,用于组织一组相关的类和接口。从概念上讲,您可以将软件包视为类似于计算机上的不同文件夹。您可以将HTML页面保留在一个文件夹中,将图像保留在另一个文件夹中,并将脚本或应用程序保留在另一个文件夹中。因为用Java编程语言编写的软件可以由成百上千个单独的类组成,所以通过将相关的类和接口放入包中来使事情井井有条是很有意义的。
Java平台提供了适合在您自己的应用程序中使用的庞大的类库(一组软件包)。该库称为“应用程序编程接口”或简称“ API”。它的程序包代表与通用编程最常关联的任务。例如,一个String对象包含字符串的状态和行为。 File对象允许程序员轻松创建,删除,检查,比较或修改文件系统上的文件;套接字对象允许创建和使用网络套接字;各种GUI对象控制按钮和复选框,以及与图形用户界面有关的其他任何内容。从字面上看,有数千种课程可供选择。程序员,这使您可以专注于特定应用程序的设计,而不是使其工作所需的基础结构。
Java Platform API Specification包含Java SE平台提供的所有软件包,接口,类,字段和方法的完整列表。在浏览器中加载页面并将其添加为书签。作为程序员,它将成为您最重要的参考文档。
Questions
- Real-world objects contain _ and _.
- A software object’s state is stored in ___.
- A software object’s behavior is exposed through ___.
- Hiding internal data from the outside world, and accessing it only through publicly exposed methods is known as data ___.
- A blueprint for a software object is called a ___.
- Common behavior can be defined in a _ and inherited into a _ using the ___ keyword.
- A collection of methods with no implementation is called an ___.
- A namespace that organizes classes and interfaces by functionality is called a ___.
- The term API stands for ___?
Exercises
- Create new classes for each real-world object that you observed at the beginning of this trail. Refer to the Bicycle class if you forget the required syntax.
- For each new class that you’ve created above, create an interface that defines its behavior, then require your class to implement it. Omit one or two methods and try compiling. What does the error look like?
语言基础
变量
您已经了解到对象存储在字段中。但是,Java编程语言也使用术语“变量”。本节讨论这种关系,以及变量命名规则和约定,基本数据类型(原始类型,字符串和数组),默认值和文字。
经营者
本节描述Java编程语言的运算符。它首先显示最常用的运算符,然后显示最不常用的运算符。每个讨论都包含可编译和运行的代码示例。
表达式,语句和块
运算符可用于构建表达式,以计算值。表达式是语句的核心组成部分;语句可以分为多个块。本节使用您已经看到的示例代码讨论表达式,语句和块。
控制流语句
本节描述Java编程语言支持的控制流语句。它涵盖了决策,循环和分支语句,使您的程序可以有条件地执行特定的代码块。
变量
操作符
表达式,语句和块
控制流语句
类和对象
现在,您掌握了Java编程语言的基础知识,就可以学习编写自己的类。在本课程中,您将找到有关定义自己的类的信息,包括声明成员变量,方法和构造函数。
您将学习如何使用类来创建对象,以及如何使用所创建的对象。
本课还介绍了其他类中的嵌套类以及枚举
类
本节向您展示类的剖析,以及如何声明字段,方法和构造函数。
对象
本节介绍创建和使用对象。您将学习如何实例化一个对象,以及实例化后如何使用点运算符访问该对象的实例变量和方法。
有关类的更多信息
本节介绍了类的更多方面,这些方面取决于使用对象引用和上一节中学习的点运算符:从方法,this关键字,类与实例成员以及访问控制返回值。
嵌套类
涵盖了静态嵌套类,内部类,匿名内部类,局部类和lambda表达式。还有关于何时使用哪种方法的讨论。
枚举类型
本节介绍枚举和专用类,这些类使您可以定义和使用常量集。
类
在名为“面向对象编程概念”的课程中,对面向对象概念的介绍以自行车类为例,赛车,山地自行车和双人自行车是子类。 这是一个可能的Bicycle类实现的示例代码,为您提供类声明的概述。 本课的后续部分将备份并逐步解释类声明。 目前,不要担心细节。
1 | public class Bicycle { |
作为Bicycle的子类的MountainBike类的类声明如下所示:
1 | public class MountainBike extends Bicycle { |
MountainBike继承了Bicycle的所有字段和方法,并添加了seatHeight字段和一种设置方法(山地自行车的座椅可以根据地形要求上下移动)。
声明类
您已经看到以以下方式定义的类:
1 | class MyClass { |
这是一个类声明。类主体(大括号之间的区域)包含提供从类创建的对象的生命周期的所有代码:用于初始化新对象的构造函数,用于提供类及其对象状态的字段的声明,以及实现类及其对象行为的方法。
前面的类声明是最小的。它仅包含类声明中必需的那些组件。您可以在类声明的开头提供有关该类的更多信息,例如其超类的名称,是否实现任何接口等等。例如,
1 | class MyClass extends MySuperClass implements YourInterface { |
表示MyClass是MySuperClass的子类,并且它实现YourInterface接口。
您还可以在开始时添加诸如public或private之类的修饰符,因此您可以看到类声明的开头可能会变得非常复杂。本课后面将讨论修饰符public和private,这些修饰符确定哪些其他类可以访问MyClass。关于接口和继承的课程将说明如何以及为什么要在类声明中使用扩展并实现关键字。目前,您无需担心这些额外的并发症。
通常,类声明可以按顺序包括以下组件:
- 修饰符,例如
public,private以及以后会遇到的许多其他修饰符。 - 类名,首字母大写为约定。
- 类的父级(超类)的名称(如果有的话),以关键字
extends开头。一个类只能扩展(子类)一个父级。 - 由类实现的接口的列表,以逗号分隔(如果有的话),并以关键字
Implements开头。一个 类可以实现多个接口。 - 类主体,用大括号{}包围。
声明成员变量
有几种变量:
- 类中的成员变量-这些称为字段。
- 方法或代码块中的变量-这些称为局部变量。
- 方法声明中的变量-这些称为参数。
Bicycle类使用以下代码行定义其字段:
1 | public int cadence; |
字段声明按顺序由三个部分组成:
- 零个或多个修饰符,例如public或private。
- 字段的类型。
- 字段名称。
Bicycle的字段被称为节奏,档位和速度,并且都是数据类型整数(int)。 public关键字将这些字段标识为公共成员,任何可以访问该类的对象都可以访问它们。
访问修饰符
使用第一个(最左侧)修饰符可以控制其他哪些类可以访问成员字段。目前,仅考虑公开和私有。其他访问修饰符将在后面讨论。
- 公共修饰符-该字段可从所有类访问。
- private修饰符-该字段只能在其自己的类中访问。
本着封装的精神,通常将字段设为私有。这意味着只能从Bicycle类直接访问它们。但是,我们仍然需要访问这些值。这可以通过添加公共方法来间接完成,这些方法可以为我们获取字段值:
1 | public class Bicycle { |
种类
所有变量必须具有类型。您可以使用基本类型,例如int,float,boolean等。也可以使用引用类型,例如字符串,数组或对象。
变量名
所有变量,无论它们是字段,局部变量还是参数,都遵循“语言基础”课程“变量—命名”中涉及的相同命名规则和约定。
在本课程中,请注意,方法和类名使用相同的命名规则和约定,但
类名的首字母应大写,并且
方法名称中的第一个(或唯一)词应为动词。
定义方法
构造方法支持
传递信息给方法或构造方法
对象
创建对象
使用对象
有关类的更多信息
从方法返回值
使用关键字
控制类成员的访问
理解类成员
初始化字段
总结类和对象的创建和使用
问题和练习:类
问题和练习:对象
嵌套类
Java编程语言允许您在另一个类中定义一个类。 这样的类称为嵌套类,并在此处进行说明:
1 | class OuterClass { |
术语:嵌套类分为两类:静态和非静态。 声明为静态的嵌套类称为静态嵌套类。 非静态嵌套类称为内部类。
1 | class OuterClass { |
嵌套类是其封闭类的成员。非静态嵌套类(内部类)可以访问封闭类的其他成员,即使它们被声明为私有的也是如此。静态嵌套类无权访问封闭类的其他成员。作为OuterClass的成员,可以将嵌套类声明为私有,公共,受保护或包私有。 (回想一下,外部类只能声明为公共或包私有。)
为什么要使用嵌套类?
使用嵌套类的令人信服的原因包括:
- 这是一种对仅在一个地方使用的类进行逻辑分组的方法:如果一个类仅对另一个类有用,那么将其嵌入该类并将两者保持在一起是合乎逻辑的。嵌套此类“帮助程序类”可使它们的程序包更加简化。
- 它增加了封装:考虑两个顶级类A和B,其中B需要访问A的成员,否则将其声明为私有。通过将类B隐藏在类A中,可以将A的成员声明为私有,而B可以访问它们。另外,B本身可以对外界隐藏。
- 它可以导致更具可读性和可维护性的代码:在顶级类中嵌套小型类会使代码更靠近使用位置。
静态嵌套类
与类方法和变量一样,静态嵌套类与其外部类相关联。与静态类方法一样,静态嵌套类不能直接引用其封闭类中定义的实例变量或方法:它只能通过对象引用来使用它们。
注意:静态嵌套类与它的外部类(和其他类)的实例成员进行交互,就像其他任何顶级类一样。实际上,静态嵌套类在行为上是顶级类,为了包装方便,该顶级类已嵌套在另一个顶级类中。
静态嵌套类使用封闭的类名称访问:
1 | OuterClass.StaticNestedClass |
例如,要为静态嵌套类创建一个对象,请使用以下语法:
1 | OuterClass.StaticNestedClass nestedObject = |
内部类
与实例方法和变量一样,内部类与其所在类的实例相关联,并且可以直接访问该对象的方法和字段。另外,由于内部类与实例相关联,因此它本身不能定义任何静态成员。
作为内部类实例的对象存在于外部类实例中。考虑以下类别:
1 | class OuterClass { |
InnerClass的实例只能存在于OuterClass的实例中,并且可以直接访问其封闭实例的方法和字段。
要实例化内部类,必须首先实例化外部类。然后,使用以下语法在外部对象内创建内部对象:
1 | OuterClass.InnerClass innerObject = externalObject.new InnerClass(); |
重影
如果在特定范围(例如内部类或方法定义)中的类型声明(例如成员变量或参数名称)与封闭范围中的另一个声明具有相同的名称,则该声明将覆盖该声明封闭范围。您不能仅凭其名称引用带阴影的声明。下面的示例ShadowTest演示了这一点:
1 | public class ShadowTest { |
以下是此示例的输出:
1 | x = 23 |
此示例定义了三个名为x的变量:ShadowTest类的成员变量,内部类FirstLevel的成员变量以及methodInFirstLevel方法中的参数。定义为方法methodInFirstLevel的参数的变量x遮盖了内部类FirstLevel的变量。因此,在方法methodInFirstLevel中使用变量x时,它引用方法参数。要引用内部类FirstLevel的成员变量,请使用关键字this表示封闭范围:
1 | System.out.println(“ this.x =” + this.x); |
请参阅成员变量,这些成员变量使用它们所属的类名将更大的范围括起来。例如,以下语句从methodInFirstLevel方法访问ShadowTest类的成员变量:
1 | System.out.println("ShadowTest.this.x =" + ShadowTest.this.x); |
序列化
强烈建议不要对内部类(包括本地类和匿名类)进行序列化。 当Java编译器编译某些构造(例如内部类)时,它会创建综合构造。 它们是类,方法,字段以及其他在源代码中没有相应构造的构造。 合成构造使Java编译器无需更改JVM就可以实现新的Java语言功能。 但是,合成构造在不同的Java编译器实现中可能有所不同,这意味着.class文件在不同的实现中也可能有所不同。 因此,如果序列化一个内部类,然后使用其他JRE实现对其进行反序列化,则可能会遇到兼容性问题。 有关在编译内部类时生成的综合构造的更多信息,请参见“获取方法参数的名称”一节中的“隐式参数和综合参数”部分。
内部类例子
本地类
匿名类
Lambda表达式
什么时候使用内部类,本地类,匿名类,Lambda表达式
如嵌套类一节中所述,嵌套类使您能够对仅在一个地方使用的类进行逻辑分组,增加封装的使用,并创建更具可读性和可维护性的代码。本地类,匿名类和lambda表达式也具有这些优点。但是,它们旨在用于更特定的情况:
本地类:如果需要创建一个类的多个实例,访问其构造函数或引入新的命名类型(例如,因为稍后需要调用其他方法),请使用它。
匿名类:如果需要声明字段或其他方法,请使用它。
-
- 如果要封装要传递给其他代码的单个行为单位,请使用它。例如,如果要在集合的每个元素上执行特定操作,流程完成或流程遇到错误时,可以使用lambda表达式。
- 如果您需要功能接口的简单实例并且不符合上述条件(例如,不需要构造函数,命名类型,字段或其他方法),请使用它。
嵌套类:如果您的要求与本地类的要求相似,并且您想使该类型更广泛地使用,并且您不需要访问本地变量或方法参数,请使用它。
- 如果您需要访问封闭实例的非公共字段和方法,请使用非静态嵌套类(或内部类)。如果您不需要此访问,请使用静态嵌套类。
问题和练习:内部类
枚举类型
问题和练习:枚举类型
注解
接口和继承
Numbers和Strings
泛型
包
基本Java类
有关异常,基本输入/输出,并发,正则表达式和平台环境的课程。
高级
准备深入研究该技术了吗?请参阅以下主题:
- 集合-有关使用和扩展Java集合框架的课程。
- Lambda表达式:了解如何以及为什么在应用程序中使用Lambda表达式。
- 聚合操作:探索聚合操作,流和Lambda表达式如何协同工作以提供强大的过滤功能。
- 在JAR文件中打包程序–创建和签名JAR文件的课程。
- 国际化–设计软件的简介,以便可以轻松地将其修改(本地化)为各种语言和地区。
- 反射–表示(“反射”)当前Java虚拟机中的类,接口和对象的API。
- 安全性– Java平台功能可帮助保护应用程序免受恶意软件的侵害。
- JavaBeans – Java平台的组件技术。
- 扩展机制–如何使自定义API对Java平台上运行的所有应用程序可用。
- 泛型–类型系统的增强,它支持对各种类型的对象进行操作,同时提供编译时类型安全。
集合
Lambda表达式
匿名类的一个问题是,如果匿名类的实现非常简单(例如仅包含一个方法的接口),则匿名类的语法可能看起来笨拙且不清楚。 在这些情况下,您通常试图将功能作为参数传递给另一种方法,例如当某人单击按钮时应采取的措施。 Lambda表达式使您能够执行此操作,将功能视为方法参数,或将代码视为数据。
上一节“匿名类”介绍了如何在不给基类命名的情况下实现它。 尽管这通常比命名类更简洁,但是对于仅具有一种方法的类,即使是匿名类也显得有些繁琐。 Lambda表达式使您可以更紧凑地表达单方法类的实例。
本节涵盖以下主题:
Lambda表达式的理想用例
假设您正在创建一个社交网络应用程序。您想创建一个功能,使管理员可以对满足特定条件的社交网络应用程序成员执行任何类型的操作,例如发送消息。下表详细描述了该用例:
| Field | Description |
|---|---|
| Name | Perform action on selected members |
| Primary Actor | Administrator |
| Preconditions | Administrator is logged in to the system. |
| Postconditions | 仅对符合指定条件的成员执行操作。 |
| Main Success Scenario | 管理员指定对其执行特定操作的成员条件。 管理员指定要对那些选定成员执行的操作。 管理员选择提交按钮。 系统查找与指定条件匹配的所有成员。 系统对所有匹配成员执行指定的操作。 |
| Extensions | 1a. 管理员可以选择在指定操作之前或选择“提交”按钮之前预览符合指定条件的成员。 |
| Frequency of Occurrence | Many times during the day. |
假设此社交网络应用程序的成员由以下Person类表示:
1 | public class Person { |
假设您的社交网络应用程序的成员存储在List <Person>实例中。
本节以对这种用例的幼稚方法开始。 它使用本地和匿名类对该方法进行了改进,然后使用lambda表达式以一种高效而简洁的方法结束了。 在示例RosterTest中找到本节中描述的代码摘录。
方法1:创建搜索匹配一个特征的成员的方法
一种简单的方法是创建几种方法。 每种方法都会搜索与一个特征(例如性别或年龄)相匹配的成员。 下面的方法将打印超过指定年龄的成员:
1 | public static void printPersonsOlderThan(List<Person> roster, int age) { |
注意:List是有序Collection。集合是将多个元素分组为一个单元的对象。集合用于存储,检索,操作和传达聚合数据。有关集合的更多信息,请参阅“集合”路径。
这种方法可能会使您的应用程序变脆,这是由于引入了更新(例如更新的数据类型)而导致应用程序无法工作的可能性。假设您升级了应用程序,并更改了Person类的结构,使其包含不同的成员变量;也许该班级使用不同的数据类型或算法记录和衡量年龄。您将不得不重写许多API来适应此更改。另外,这种方法是不必要的限制。例如,如果要打印小于特定年龄的成员该怎么办?
方法2:创建更通用的搜索方法
以下方法比printPersonsOlderThan更通用;它打印指定年龄范围内的成员:
1 | public static void printPersonsWithinAgeRange( |
如果要打印指定性别或指定性别和年龄范围的组合,该怎么办? 如果您决定更改Person类并添加其他属性(例如关系状态或地理位置)怎么办? 尽管此方法比printPersonsOlderThan更通用,但是尝试为每个可能的搜索查询创建单独的方法仍会导致代码变脆。 相反,您可以在其他类中分隔指定要搜索标准的代码。
方法3:在本地类中指定搜索条件代码
下面的方法打印与您指定的搜索条件匹配的成员:
1 | public static void printPersons( |
此方法通过调用方法tester.test来检查List参数名册中包含的每个Person实例是否满足CheckPerson参数测试器中指定的搜索条件。 如果方法tester.test返回一个真值,则在Person实例上调用方法printPersons。
要指定搜索条件,请实现CheckPerson界面:
1 | interface CheckPerson { |
下列类通过指定方法test的实现来实现CheckPerson接口。 此方法过滤在美国符合资格使用“选择性服务”的成员:如果其Person参数是男性且年龄在18至25之间,则它返回一个真值:
1 | class CheckPersonEligibleForSelectiveService implements CheckPerson { |
要使用此类,请创建该类的新实例并调用printPersons方法:
1 | printPersons( |
尽管这种方法不那么灵活(如果更改Person的结构,您不必重写方法),但是您仍然拥有其他代码:计划在应用程序中执行的每个搜索都需要一个新接口和一个本地类。 因为CheckPersonEligibleForSelectiveService实现了一个接口,所以您可以使用匿名类而不是本地类,并且无需为每次搜索声明一个新类。
方法4:在匿名类中指定搜索条件代码
以下调用方法printPersons的参数之一是一个匿名类,该类过滤在美国符合资格参加选择性服务的成员:男性,年龄在18至25岁之间:
1 | printPersons( |
这种方法减少了所需的代码量,因为您不必为要执行的每个搜索创建一个新类。 但是,考虑到CheckPerson接口仅包含一种方法,匿名类的语法非常庞大。 在这种情况下,您可以使用lambda表达式代替匿名类,如下一节所述。
方法5:使用Lambda表达式指定搜索条件代码
CheckPerson接口是功能接口。 功能接口是仅包含一种抽象方法的任何接口。 (一个功能接口可能包含一个或多个默认方法或静态方法。)由于一个功能接口仅包含一个抽象方法,因此在实现该方法时可以省略该方法的名称。 为此,您可以使用lambda表达式(而不是使用匿名类表达式),该表达式在以下方法调用中突出显示:
1 | printPersons( |
有关如何定义lambda表达式的信息,请参见Lambda表达式的语法。
您可以使用标准功能接口代替CheckPerson接口,从而进一步减少了所需的代码量。
方法6:将标准功能接口与Lambda表达式一起使用
重新考虑CheckPerson接口:
1 | interface CheckPerson { |
这是一个非常简单的界面。 这是一个功能接口,因为它仅包含一个抽象方法。 此方法采用一个参数并返回布尔值。 该方法是如此简单,以至于在您的应用程序中定义一个方法可能不值得。 因此,JDK定义了几个标准功能接口,您可以在包java.util.function中找到它们。
例如,您可以使用Predicate
1 | interface Predicate<T> { |
接口Predicate
1 | interface Predicate<Person> { |
此参数化类型包含一个方法,该方法具有与CheckPerson.boolean test(Person p)相同的返回类型和参数。 因此,可以使用Predicate
1 | public static void printPersonsWithPredicate( |
结果,以下方法调用与您在方法3中调用printPersons时相同:在本地类中指定搜索条件代码以获取有资格使用选择性服务的成员:
1 | printPersonsWithPredicate( |
这不是使用lambda表达式的唯一方法。 以下方法建议了使用lambda表达式的其他方法。
方法7:在整个应用程序中使用Lambda表达式
重新考虑方法printPersonsWithPredicate,看看还能在哪里使用lambda表达式:
1 | public static void printPersonsWithPredicate( |
此方法检查List参数名册中包含的每个Person实例是否满足Predicate参数测试器中指定的条件。如果Person实例确实满足测试人员指定的条件,则在Person实例上调用方法printPersron。
除了可以调用方法printPerson之外,您还可以指定其他操作来对那些满足测试人员指定条件的Person实例执行。您可以使用lambda表达式指定此操作。假设您想要一个类似于printPerson的lambda表达式,该表达式需要一个参数(Person类型的对象)并返回void。请记住,要使用lambda表达式,您需要实现一个功能接口。在这种情况下,您需要一个包含抽象方法的功能接口,该抽象方法可以采用Person类型的一个参数并返回void。 Consumer
1 | public static void processPersons( |
因此,以下方法调用与您在方法3中调用printPersons时相同:在本地类中指定搜索条件代码以获取符合选择性服务资格的成员。 用于打印成员的lambda表达式突出显示:
1 | processPersons( |
如果您想对会员个人资料进行更多处理而不是打印出来,该怎么办。 假设您要验证成员的个人资料或检索他们的联系信息? 在这种情况下,您需要一个功能接口,其中包含一个返回值的抽象方法。 Function
1 | public static void processPersonsWithFunction( |
以下方法从名册中包含有资格使用“选择性服务”的每个成员中检索电子邮件地址,然后进行打印:
1 | processPersonsWithFunction( |
方法8:更广泛地使用泛型
重新考虑方法processPersonsWithFunction。 以下是其通用版本,该通用版本接受包含任何数据类型的元素的集合作为参数:
1 | public static <X, Y> void processElements( |
要打印符合选择服务资格的成员的电子邮件地址,请按以下方式调用processElements方法:
1 | processElements( |
此方法调用执行以下操作:
- 从收集源获取对象的源。 在此示例中,它从集合名册中获取Person对象的源。 请注意,集合名册是List类型的集合,也是Iterable类型的对象。
- 筛选与谓词对象测试器匹配的对象。 在此示例中,谓词对象是一个lambda表达式,用于指定哪些成员符合选择服务的条件。
- 将每个过滤的对象映射到Function对象映射器指定的值。 在此示例中,Function对象是一个lambda表达式,该表达式返回成员的电子邮件地址。
- 对使用者对象块指定的每个映射对象执行操作。 在此示例中,Consumer对象是一个lambda表达式,该表达式输出一个字符串,该字符串是Function对象返回的电子邮件地址。
您可以将这些操作中的每一个替换为聚合操作。
方法9:使用接受Lambda表达式作为参数的聚合操作
下面的示例使用聚合操作来打印集合名册中包含的符合选择性服务资格的那些成员的电子邮件地址:
1 | roster |
下表映射了processElements方法使用相应的聚合操作执行的每个操作:
processElements Action |
Aggregate Operation |
|---|---|
| Obtain a source of objects | Stream<E> **stream**() |
Filter objects that match a Predicate object |
Stream<T> **filter**(Predicate<? super T> predicate) |
Map objects to another value as specified by a Function object |
<R> Stream<R> **map**(Function<? super T,? extends R> mapper) |
Perform an action as specified by a Consumer object |
void **forEach**(Consumer<? super T> action) |
操作filter,map和forEach是聚合操作。 聚合操作从流而不是直接从集合中处理元素(这就是在本示例中调用的第一个方法是流的原因)。 流是元素序列。 与集合不同,它不是存储元素的数据结构。 取而代之的是,流通过管道携带来自源(如集合)的值。 流水线是一系列流操作,在此示例中为filtermap-forEach。 此外,聚合操作通常接受lambda表达式作为参数,使您能够自定义它们的行为。
有关聚合操作的更详尽讨论,请参阅“聚合操作”课程。
GUI应用程序中的Lambda表达式
为了处理图形用户界面(GUI)应用程序中的事件,例如键盘操作,鼠标操作和滚动操作,通常需要创建事件处理程序,这通常涉及实现特定的界面。通常,事件处理程序接口是功能接口。他们往往只有一种方法。
在JavaFX示例HelloWorld.java(在上一节“匿名类”中讨论过)中,您可以在此语句中用lambda表达式替换突出显示的匿名类:
1 | btn.setOnAction(new EventHandler<ActionEvent>() { |
方法调用btn.setOnAction指定当您选择由btn对象表示的按钮时发生的情况。此方法需要一个EventHandler
1 | btn.setOnAction( |
Lambda表达式语法
Lambda表达式包含以下内容:
- 用括号括起来的形式参数的逗号分隔列表。 CheckPerson.test方法包含一个参数p,它表示Person类的实例。
注意:您可以省略lambda表达式中参数的数据类型。此外,如果只有一个参数,则可以省略括号。例如,以下lambda表达式也有效:
1 | p-> p.getGender()== Person.Sex.MALE |
箭头标记->
主体,由单个表达式或语句块组成。本示例使用以下表达式:
1 | p.getGender()== Person.Sex.MALE |
如果指定单个表达式,则Java运行时将评估该表达式,然后返回其值。另外,您可以使用return语句:
1 | p -> { |
return语句不是表达式。在lambda表达式中,必须将语句括在大括号({})中。但是,您不必在括号中包含void方法调用。例如,以下是有效的lambda表达式:
1 | email -> System.out.println(email) |
注意,lambda表达式看起来很像方法声明。您可以将lambda表达式视为匿名方法,即没有名称的方法。
以下示例Calculator是使用多个形式参数的lambda表达式的示例:
1 | public class Calculator { |
方法operatorBinary对两个整数操作数执行数学运算。 该操作本身由IntegerMath的实例指定。 该示例使用lambda表达式定义了两个操作:加法和减法。 该示例打印以下内容:
1 | 40 + 2 = 42 |
访问封闭范围的局部变量
像本地和匿名类一样,lambda表达式可以捕获变量。 它们对封闭范围的局部变量具有相同的访问权限。 但是,与本地和匿名类不同,lambda表达式没有任何阴影问题(有关更多信息,请参见阴影)。 Lambda表达式具有词法范围。 这意味着它们不会从超类型继承任何名称,也不会引入新的作用域范围。 解释lambda表达式中的声明就像在封闭环境中一样。 以下示例LambdaScopeTest演示了这一点:
1 | import java.util.function.Consumer; |
例子生成的输出打印:
1 | x = 23 |
如果在lambda表达式myConsumer的声明中用参数x代替y,则编译器将生成错误:
1 | Consumer<Integer> myConsumer = (x) -> { |
编译器会生成错误“方法x中已经定义了变量x,因为methodInFirstLevel(int)已定义”,因为lambda表达式未引入新的作用域范围。因此,您可以直接访问封闭范围的字段,方法和局部变量。例如,lambda表达式直接访问方法methodInFirstLevel的参数x。要访问封闭类中的变量,请使用关键字this。在此示例中,this.x引用成员变量FirstLevel.x。
但是,与本地和匿名类一样,lambda表达式只能访问最终或有效最终的封闭块的局部变量和参数。例如,假设您在methodInFirstLevel定义语句之后立即添加以下赋值语句:
1 | void methodInFirstLevel(int x){ |
由于该赋值语句,变量FirstLevel.x不再有效地变为final。结果,Java编译器生成一条错误消息,类似于“从lambda表达式引用的本地变量必须是final或有效地是final”,其中lambda表达式myConsumer尝试访问FirstLevel.x变量:
1 | System.out.println("x = " + x); |
目标类型
您如何确定Lambda表达式的类型?回忆一下选择了男性且年龄在18至25岁之间的成员的lambda表达式:
1 | p-> p.getGender()== Person.Sex.MALE |
此lambda表达式用于以下两种方法:
方法3中的在本地类中指定搜索条件代码:
public static void printPersons(List<Person> roster, CheckPerson tester)方法6:使用带有Lambda表达式的标准功能接口的
public void printPersonsWithPredicate(List<Person> roster, Predicate<Person> tester)
当Java运行时调用方法printPersons时,它期望的数据类型为CheckPerson,因此lambda表达式就是这种类型。但是,当Java运行时调用方法printPersonsWithPredicate时,期望的数据类型为Predicate<Person>,因此lambda表达式就是这种类型。这些方法期望的数据类型称为目标类型。为了确定lambda表达式的类型,Java编译器使用找到lambda表达式的上下文或情况的目标类型。因此,您只能在Java编译器可以确定目标类型的情况下使用lambda表达式:
变量声明
作业
退货声明
数组初始化器
方法或构造函数参数
Lambda表达体
条件表达式,?:
转换表达式
目标类型和方法参数
对于方法参数,Java编译器使用其他两种语言功能确定目标类型:重载解析和类型参数推断。
考虑以下两个功能接口(java.lang.Runnable和java.util.concurrent.Callable
1 | public interface Runnable { |
方法Runnable.run不返回值,而Callable<V> .call则返回值。
假设您已按以下方式重载了方法调用(有关重载方法的更多信息,请参见定义方法):
1 | void invoke(Runnable r) { |
以下语句将调用哪种方法?
1 | String s = invoke(() -> "done"); |
将调用invoke(Callable<T>)方法,因为该方法返回一个值。方法invoke(Runnable)则没有。在这种情况下,lambda表达式()->“ done”的类型为Callable <T>。
序列化
如果lambda表达式的目标类型和捕获的参数可序列化,则可以对其进行序列化。但是,像内部类一样,强烈建议不要对lambda表达式进行序列化。
方法引用
您使用lambda表达式创建匿名方法。 但是,有时lambda表达式除了调用现有方法外什么也不做。 在这种情况下,通常更容易按名称引用现有方法。 方法引用使您可以执行此操作; 它们是紧凑的,易于阅读的lambda表达式,用于已经具有名称的方法。
再次考虑Lambda表达式部分中讨论的Person类:
1 | public class Person { |
假设您的社交网络应用程序的成员包含在一个数组中,并且您想按年龄对数组进行排序。您可以使用以下代码(在示例MethodReferencesTest示例中找到本节中描述的代码摘录):
1 | Person[] rosterAsArray = roster.toArray(new Person[roster.size()]); |
这种调用的方法签名如下:
1 | static <T> void sort(T[] a, Comparator<? super T> c) |
请注意,接口Comparator是功能接口。因此,可以使用lambda表达式来代替定义然后创建实现Comparator的类的新实例:
1 | Arrays.sort(rosterAsArray, |
但是,这种用于比较两个Person实例的出生日期的方法已经作为Person.compareByAge存在。您可以改为在lambda表达式的主体中调用此方法:
1 | Arrays.sort(rosterAsArray, |
由于此lambda表达式调用现有方法,因此可以使用方法引用代替lambda表达式:
1 | Arrays.sort(rosterAsArray, Person::compareByAge); |
方法引用Person :: compareByAge在语义上与lambda表达式(a,b)-> Person.compareByAge(a,b)相同。每个都有以下特征:
- 它的形式参数列表是从Comparator
.compare复制的,该文件是(Person,Person)。 - 它的主体调用方法Person.compareByAge。
方法引用的种类
有4种方法引用:
| Kind | Example |
|---|---|
| Reference to a static method | ContainingClass::staticMethodName |
| Reference to an instance method of a particular object | containingObject::instanceMethodName |
| Reference to an instance method of an arbitrary object of a particular type | ContainingType::methodName |
| Reference to a constructor | ClassName::new |
静态方法引用
方法引用Person :: compareByAge是对静态方法的引用。
引用特定对象的实例方法
以下是对特定对象的实例方法的引用示例:
1 | class ComparisonProvider { |
方法引用myComparisonProvider :: compareByName调用方法compareByName,它是对象myComparisonProvider的一部分。 JRE推断方法类型参数,在这种情况下为(Person,Person)。
以下是对特定类型的任意对象的实例方法的引用示例:
1 | String[] stringArray = { "Barbara", "James", "Mary", "John", |
方法参考String :: compareToIgnoreCase的等效lambda表达式将具有形式参数列表(字符串a,字符串b),其中a和b是用于更好地描述此示例的任意名称。 方法引用将调用方法a.compareToIgnoreCase(b)。
构造方法引用
您可以使用名称new来引用与静态方法相同的方法来引用构造函数。以下方法将元素从一个集合复制到另一个:
1 | public static <T, SOURCE extends Collection<T>, DEST extends Collection<T>> |
功能接口Supplier包含一个方法get,该方法不带任何参数并返回一个对象。因此,您可以使用lambda表达式调用方法transferElements,如下所示:
1 | Set<Person> rosterSetLambda = |
您可以使用构造函数引用代替lambda表达式,如下所示:
1 | Set<Person> rosterSet = transferElements(roster, HashSet::new); |
Java编译器推断您要创建一个HashSet集合,其中包含Person类型的元素。另外,您可以指定如下:
1 | Set<Person> rosterSet = transferElements(roster, HashSet<Person>::new); |
聚合操作
注意:为了更好地理解本节中的概念,请查看“ Lambda表达式和方法参考”部分。
您使用什么集合?您不只是将对象存储在集合中并留在其中。在大多数情况下,您可以使用集合来检索存储在其中的项目。
再次考虑Lambda表达式部分中描述的方案。假设您正在创建一个社交网络应用程序。您想创建一个功能,使管理员可以对满足特定条件的社交网络应用程序成员执行任何类型的操作,例如发送消息。
和以前一样,假定此社交网络应用程序的成员由以下Person类表示:
1 | public class Person { |
以下示例通过for-each循环打印集合名册中包含的所有成员的名称:
1 | for (Person p : roster) { |
以下示例显示集合名册中包含但具有聚合操作forEach的所有成员:
1 | roster |
尽管在此示例中,使用聚合操作的版本比使用for-each循环的版本长,但是您将看到使用批量数据操作的版本对于更复杂的任务将更加简洁。
涵盖以下主题:
在示例BulkDataOperationsExamples中找到本节中描述的代码摘录。
管道和流
管道是一系列聚合操作。下面的示例使用包含聚合操作过滤器和forEach的管道来打印集合列表中包含的公成员。
1 | roster |
将此示例与以下示例进行比较,该示例将使用for-each循环打印集合名册中包含的公成员:
1 | for (Person p : roster) { |
管道包含以下组件:
源:可以是集合,数组,生成器函数或I / O通道。在此示例中,源是集合名册。
零个或多个中间操作。诸如过滤器之类的中间操作产生新的流。
流是元素序列。与集合不同,它不是存储元素的数据结构。相反,流通过管道从源携带值。本示例通过调用方法流从集合名册创建流。
筛选器操作返回一个新流,该流包含与其谓词相匹配的元素(此操作的参数)。在此示例中,谓词是lambda表达式
e-> e.getGender()== Person.Sex.MALE。如果对象e的性别字段的值为Person.Sex.MALE,则返回布尔值true。因此,此示例中的筛选操作返回一个流,其中包含集合花名册中的所有公成员。终端操作。终端操作(例如forEach)会产生非流结果,例如原始值(如double值),集合,或者在forEach的情况下根本没有任何结果。在此示例中,forEach操作的参数是lambda表达式
e-> System.out.println(e.getName()),该表达式在对象e上调用方法getName。 (Java运行时和编译器推断对象e的类型为Person。)
下面的示例使用包含聚合操作filter,mapToInt和average的管道来计算集合名册中包含的所有男性成员的平均年龄:
1 | double average = roster |
mapToInt操作将返回一个新的IntStream类型的流(该流仅包含整数值)。该操作将其参数中指定的功能应用于特定流中的每个元素。在此示例中,函数是Person :: getAge,这是一个返回成员年龄的方法引用。 (或者,您可以使用lambda表达式e-> e.getAge()。)因此,本示例中的mapToInt操作返回一个流,其中包含集合名册中所有男性成员的年龄。
平均操作将计算IntStream类型的流中包含的元素的平均值。它返回类型为OptionalDouble的对象。如果流不包含任何元素,则平均操作将返回OptionalDouble的空实例,并且调用方法getAsDouble会引发NoSuchElementException。 JDK包含许多终端操作,例如平均值,它们通过组合流的内容返回一个值。这些操作称为归约操作。有关更多信息,请参见Reduction部分。
集合操作和迭代器之间的差异
聚合操作(例如forEach)似乎像迭代器。但是,它们有几个基本差异:
它们使用内部迭代:聚合操作不包含诸如next的方法来指示它们处理集合的下一个元素。使用内部委派,您的应用程序确定要迭代的集合,而JDK确定如何迭代该集合。通过外部迭代,您的应用程序可以确定迭代哪个集合以及如何迭代。但是,外部迭代只能顺序地迭代集合的元素。内部迭代没有此限制。它可以更轻松地利用并行计算的优势,这涉及将一个问题分解为多个子问题,同时解决这些问题,然后将这些解决方案的结果组合为子问题。有关更多信息,请参见并行性一节。
它们处理流中的元素:聚合操作从流中而不是直接从集合中处理元素。因此,它们也称为流操作。
它们支持将行为作为参数:您可以将lambda表达式指定为大多数聚合操作的参数。这使您可以自定义特定聚合操作的行为。
Reduction
“汇总操作”部分描述了以下操作流程,该操作流程计算了收集名单中所有男性成员的平均年龄:
1 | double average = roster |
JDK包含许多终端操作(例如平均值,总和,最小值,最大值和计数),这些操作通过组合流的内容来返回一个值。这些操作称为归约操作。 JDK还包含归约操作,这些操作返回集合而不是单个值。许多归约运算执行特定任务,例如查找值的平均值或将元素分组为类别。但是,JDK为您提供了通用的减少和收集操作,本节将对此进行详细介绍。
本节涵盖以下主题:
您可以在示例ReductionExamples中找到本节中描述的代码摘录。
Stream.reduce方法
Stream.reduce方法是通用的约简操作。考虑以下管道,该管道计算集合名册中男性成员的年龄总和。它使用Stream.sum减少操作:
1 | Integer totalAge = roster |
将其与以下管道进行比较,该管道使用Stream.reduce操作计算相同的值:
1 | Integer totalAgeReduce = roster |
本示例中的reduce操作采用两个参数:
identity:如果流中没有元素,则identity元素既是reduce的初始值,也是默认结果。在此示例中,标识元素为0;这是年龄总和的初始值,如果集合名册中不存在成员,则为默认值。
accumulator:累加器函数有两个参数:约简的部分结果(在此示例中,是到目前为止所有已处理整数的总和)和流的下一个元素(在此示例中,是整数)。它返回一个新的部分结果。在此示例中,accumulator函数是一个lambda表达式,该表达式将两个Integer值相加并返回一个Integer值:
(a,b)-> a + b
reduce操作始终返回新值。但是,累加器函数每次处理流的元素时也会返回一个新值。假设您希望将流的元素简化为一个更复杂的对象,例如集合。这可能会妨碍您的应用程序的性能。如果您的reduce操作涉及将元素添加到集合中,那么每次累加器函数处理一个元素时,它都会创建一个包含该元素的新集合,这效率很低。相反,对您而言,更新现有集合会更有效。您可以使用下一节介绍的Stream.collect方法来执行此操作。
Stream.collect方法
与reduce方法(在处理元素时总是会创建新值)不同,collect方法会修改或变异现有值。
考虑如何查找流中的平均值。您需要两个数据:值的总数和这些值的总和。但是,像reduce方法和所有其他reduce方法一样,collect方法仅返回一个值。您可以创建一个包含成员变量的新数据类型,该成员变量跟踪值的总数和这些值的总和,例如以下类Averager:
1 | class Averager implements IntConsumer |
以下管道使用Averager类和collect方法来计算所有男性成员的平均年龄:
1 | Averager averageCollect = roster.stream() |
在此示例中,collect操作采用三个参数:
- supplier:supplier是工厂的职能;它构造了新的实例。对于收集操作,它将创建结果容器的实例。在此示例中,它是Averager类的新实例。
- accumulator:累加器功能将流元素合并到结果容器中。在此示例中,它通过将计数变量加1并将流元素的值添加到总成员变量中来修改
Averager结果容器,该流元素的值是代表男性成员年龄的整数。 - combiner:组合器函数采用两个结果容器并将其内容合并。在此示例中,它通过将另一个Variabler实例的count成员变量递增count变量,并将另一个
Averager实例的total成员变量的值添加到total成员变量,来修改Averager结果容器。
请注意以下几点:
- 供应商是lambda表达式(或方法引用),与reduce操作中类似于identity元素的值相反。
- 累加器和合并器函数不返回值。
- 您可以对并行流使用收集操作;有关更多信息,请参见并行性一节。 (如果使用并行流运行collect方法,那么只要组合器函数创建新对象(例如本示例中的Averager对象),JDK就会创建一个新线程。因此,您不必担心同步。)
尽管JDK为您提供了平均值操作来计算流中元素的平均值,但是如果需要从流元素中计算多个值,则可以使用collect操作和自定义类。
收集操作最适合收集。下面的示例通过collect操作将男性成员的姓名放入一个集合中:
1 | List<String> namesOfMaleMembersCollect = roster |
此版本的collect操作采用Collector类型的一个参数。此类封装用作需要三个参数(供应商,累加器和组合器函数)的collect操作中用作参数的函数。
Collector类包含许多有用的归约运算,例如将元素累积到集合中并根据各种标准对元素进行汇总。这些归约操作将返回类Collector的实例,因此您可以将它们用作收集操作的参数。
本示例使用Collectors.toList操作,该操作将流元素累积到List的新实例中。与Collectors类中的大多数操作一样,toList运算符返回Collector的实例,而不是List。
以下示例按性别对集合名册的成员进行分组:
1 | Map<Person.Sex, List<Person>> byGender = |
groupingBy操作返回一个映射,该映射的键是应用指定为其参数的lambda表达式(称为分类函数)而得到的值。在此示例中,返回的映射包含两个键:Person.Sex.MALE和Person.Sex.FEMALE。这两个键的对应值是List的实例,这些实例包含流元素,这些流元素在由分类功能处理时对应于键值。例如,与键Person.Sex.MALE对应的值是包含所有男性成员的List的实例。
以下示例检索集合名册中每个成员的名称,并按性别将其分组:
1 | Map<Person.Sex, List<String>> namesByGender = |
本示例中的groupingBy操作采用两个参数,一个分类函数和一个Collector实例。 Collector参数称为下游收集器。这是一个收集器,Java运行时将其应用于另一个收集器的结果。因此,此groupingBy操作使您可以将collect方法应用于groupingBy运算符创建的List值。本示例应用收集器映射,该映射器将映射函数Person :: getName应用于流的每个元素。因此,结果流仅包含成员名称。像此示例一样,包含一个或多个下游收集器的管道称为多级归约。
以下示例检索每个性别成员的总年龄:
1 | Map<Person.Sex, Integer> totalAgeByGender = |
reducing运算采用三个参数:
- identity:与Stream.reduce操作一样,如果流中没有元素,则identity元素既是reduce的初始值,也是默认结果。在此示例中,标识元素为0;这是年龄总和的初始值,如果不存在成员,则为默认值。
- mapper:缩减操作将此映射器功能应用于所有流元素。在此示例中,映射器检索每个成员的年龄。
- operation:操作功能用于减少映射的值。在此示例中,操作函数将添加整数值。
以下示例检索每种性别的成员的平均年龄:
1 | Map<Person.Sex, Double> averageAgeByGender = roster |
Parallelism
并行计算包括将一个问题分为多个子问题,同时解决这些问题(并行处理,每个子问题都在单独的线程中运行),然后将解决方案的结果组合到子问题中。 Java SE提供了fork/join框架,使您能够更轻松地在应用程序中实现并行计算。但是,在此框架下,您必须指定如何细分(划分)问题。通过聚合操作,Java运行时将为您执行此分区和解决方案合并。
在使用集合的应用程序中实现并行性的一个困难是集合不是线程安全的,这意味着多个线程在不引入线程干扰或内存一致性错误的情况下无法操纵集合。 Collections Framework提供了同步包装器,该包装器将自动同步添加到任意集合中,使其成为线程安全的。但是,同步会引入线程争用。您要避免线程争用,因为这会阻止线程并行运行。聚合操作和并行流使您能够使用非线程安全的集合实现并行性,前提是您在操作集合时不修改集合。
请注意,并行性并不会比串行执行操作自动地更快,但是如果您具有足够的数据和处理器核心,并行性可能会更快。虽然聚合操作使您可以更轻松地实现并行性,但是确定应用程序是否适合并行性仍然是您的责任。
本节涵盖以下主题:
您可以在示例ParallelismExamples中找到本节中描述的代码摘录。
并行执行流
您可以串行或并行执行流。 当流并行执行时,Java运行时将流划分为多个子流。 聚合操作迭代并并行处理这些子流,然后合并结果。
创建流时,除非另有说明,否则它始终是串行流。 要创建并行流,请调用Collection.parallelStream操作。 或者,调用操作BaseStream.parallel。 例如,以下语句并行计算所有男性成员的平均年龄:
1 | double average = roster |
并发减少
再次考虑以下示例(在“减少”部分中进行了描述),该示例按性别对成员进行分组。此示例调用collect操作,该操作将收集名册简化为Map:
1 | Map<Person.Sex, List<Person>> byGender = |
以下是并行等效项:
1 | ConcurrentMap<Person.Sex, List<Person>> byGender = |
这称为并发减少。如果满足以下所有条件的特定管道包含收集操作,则Java运行时将执行并发缩减:
- 流是并行的。
- 收集操作的参数收集器具有特征Collector.Characteristics.CONCURRENT。要确定收集器的特征,请调用Collector.characteristics方法。
- 流是无序的,或者收集器具有特征Collector.Characteristics.UNORDERED。为确保流是无序的,请调用BaseStream.unordered操作。
注意:此示例返回ConcurrentMap的实例而不是Map,并调用groupingByConcurrent操作而不是groupingBy。 (有关ConcurrentMap的更多信息,请参见并发集合部分。)与操作groupingByConcurrent不同,操作groupingBy在并行流中的性能较差。 (这是因为它通过按键合并两个映射进行操作,这在计算上是昂贵的。)类似地,与并行流相比,Collectors.toConcurrentMap操作的性能要好于Collectors.toMap操作。
Ordering
管道处理流元素的顺序取决于流是串行还是并行执行,流的源以及中间操作。 例如,考虑以下示例,该示例使用forEach操作多次打印ArrayList实例的元素:
1 | Integer[] intArray = {1, 2, 3, 4, 5, 6, 7, 8 }; |
此示例包含五个管道。它输出类似于以下内容的输出:
1 | listOfIntegers: |
此示例执行以下操作:
- 第一个管道按添加到列表中的顺序打印列表listOfIntegers的元素。
- 第二个管道将打印listOfIntegers的元素,在使用Collections.sort方法对listOfIntegers进行排序之后。。
- 第三和第四管道以明显随机的顺序打印列表的元素。请记住,在处理流元素时,流操作使用内部迭代。因此,在并行执行流时,除非由流操作另行指定,否则Java编译器和运行时将确定处理流元素的顺序,以最大程度地发挥并行计算的优势。
- 第五条管道使用forEachOrdered方法,该方法以其源指定的顺序处理流的元素,而不管您是以串行还是并行方式执行该流。请注意,如果对并行流使用诸如forEachOrdered之类的操作,则可能会失去并行性的好处。
副作用
如果方法或表达式除了返回或产生值之外还修改了计算机的状态,则它具有副作用。示例包括可变的约简(使用collect操作的约简;有关更多信息,请参见“约简”部分),以及调用System.out.println方法进行调试。 JDK很好地处理了管道中的某些副作用。特别是,collect方法设计为以并行安全的方式执行具有副作用的最常见的流操作。 forEach和peek等操作旨在解决副作用;一个返回void的lambda表达式(例如,调用System.out.println的表达式)只能产生副作用。即使这样,您也应谨慎使用forEach和peek操作;如果将这些操作之一与并行流一起使用,则Java运行时可能会从多个线程同时调用指定为其参数的lambda表达式。此外,切勿将在过滤器和映射等操作中具有副作用的lambda表达式作为参数传递。以下各节讨论了干扰和有状态的lambda表达式,这两者都是副作用的来源,并且可能返回不一致或不可预测的结果,尤其是在并行流中。但是,首先讨论懒惰的概念,因为它会直接影响干扰。
懒惰
所有中间操作都是惰性的。如果仅在需要时才求值,则表达式,方法或算法是惰性的。 (如果算法需要立即评估或处理,则非常渴望。)中间操作是延迟的,因为它们直到终端操作开始才开始处理流的内容。延迟处理流使Java编译器和运行时能够优化它们如何处理流。例如,在诸如“聚合操作”部分中描述的filter-mapToInt-average示例之类的管道中,平均值操作可以从mapToInt操作创建的流中获取前几个整数,后者从filter操作中获取元素。平均操作将重复此过程,直到从流中获取所有必需的元素,然后再计算平均值。
干扰
流操作中的Lambda表达式不应产生干扰。在管道处理流时修改流的源时会发生干扰。例如,以下代码尝试连接列表ListOfStrings中包含的字符串。但是,它将引发ConcurrentModificationException:
1 | try { |
本示例使用reduce操作(这是终端操作)将listOfStrings中包含的字符串连接为Optional<String>值。但是,此处的管道调用了中间操作peek,该操作将尝试向listOfStrings添加新元素。请记住,所有中间操作都是惰性的。这意味着此示例中的管道在调用操作get时开始执行,并在get操作完成时结束执行。 peek操作的参数尝试在管道执行期间修改流源,这会导致Java运行时抛出ConcurrentModificationException。
有状态Lambda表达式
避免在流操作中使用有状态的lambda表达式作为参数。有状态lambda表达式是一种有状态的lambda表达式,其结果取决于在管道执行期间可能更改的任何状态。以下示例通过map中间操作将List listOfIntegers中的元素添加到新的List实例中。它执行两次,首先使用串行流,然后使用并行流:
1 | List<Integer> serialStorage = new ArrayList<>(); |
Lambda表达式e-> {parallelStorage.add(e);return e; }是有状态的lambda表达式。每次运行代码时,其结果可能会有所不同。本示例打印以下内容:
1 | Serial stream: |
无论流是以串行还是并行方式执行,forEachOrdered的操作均按流指定的顺序处理元素。但是,当并行执行流时,映射操作将处理Java运行时和编译器指定的流的元素。因此,lambda表达式e-> {parallelStorage.add(e);return e;每次向代码添加元素时,List parallelStorage都会有所不同。为了获得确定性和可预测的结果,请确保流操作中的lambda表达式参数不是有状态的。
注意:此示例调用方法SynchronizedList,以便List parallelStorage是线程安全的。请记住,集合不是线程安全的。这意味着多个线程不应同时访问特定的集合。假设您在创建parallelStorage时未调用方法synchronizedList:
1 | List<Integer> parallelStorage = new ArrayList<>(); |
该示例的行为不正常,因为多个线程访问和修改parallelStorage时没有像同步这样的机制来调度特定线程何时可以访问List实例。因此,该示例可以输出类似于以下内容的输出:
1 | Parallel stream: |
问题与练习
问题
A sequence of aggregate operations is known as a ___ .
Each pipeline contains zero or more ___ operations.
Each pipeline ends with a ___ operation.
What kind of operation produces another stream as its output?
Describe one way in which the
forEachaggregate operation differs from the enhancedforstatement or iterators.True or False: A stream is similar to a collection in that it is a data structure that stores elements.
Identify the intermediate and terminal operations in this code:
1
2
3
4
5
6double average = roster
.stream()
.filter(p -> p.getGender() == Person.Sex.MALE)
.mapToInt(Person::getAge)
.average()
.getAsDouble();The code
p -> p.getGender() == Person.Sex.MALEis an example of what?The code
Person::getAgeis an example of what?Terminal operations that combine the contents of a stream and return one value are known as what?
Name one important difference between the
Stream.reducemethod and theStream.collectmethod.If you wanted to process a stream of names, extract the male names, and store them in a new
List, wouldStream.reduceorStream.collectbe the most appropriate operation to use?True or False: Aggregate operations make it possible to implement parallelism with non-thread-safe collections.
Streams are always serial unless otherwise specified. How do you request that a stream be processed in parallel?
Exercises
- Write the following enhanced
forstatement as a pipeline with lambda expressions. Hint: Use thefilterintermediate operation and theforEachterminal operation.
1 | for (Person p : roster) { |
2.Convert the following code into a new implementation that uses lambda expressions and aggregate operations instead of nested for loops. Hint: Make a pipeline that invokes the filter, sorted, and collect operations, in that order.
1 | List<Album> favs = new ArrayList<>(); |
在JAR文件中打包程序
国际化
反射
Trail:反射API
反射的用途
反射通常由需要检查或修改Java虚拟机中运行的应用程序的运行时行为的程序使用。这是一个相对高级的功能,只应由对语言基础有很深了解的开发人员使用。考虑到这一警告,反射是一种强大的技术,可以使应用程序执行原本不可能的操作。
扩展功能
应用程序可以通过使用其完全限定的名称创建可扩展性对象的实例来使用外部用户定义的类。
类浏览器和可视化开发环境
一个类浏览器需要能够枚举类的成员。可视化开发环境可以受益于利用反射中可用的类型信息来帮助开发人员编写正确的代码。
调试器和测试工具
调试器需要能够检查类的私有成员。测试工具可以利用反射来系统地调用在类上定义的可发现的集合API,以确保测试套件中的代码覆盖率很高。
反射的缺点
反射功能强大,但不应任意使用。如果可以在不使用反射的情况下执行操作,那么最好避免使用它。通过反射访问代码时,应牢记以下注意事项。
性能开销
由于反射涉及动态解析的类型,因此无法执行某些Java虚拟机优化。因此,反射操作的性能比非反射操作慢,因此应避免在对性能敏感的应用程序中经常调用的代码段中。
安全限制
反射需要运行时许可,而在安全管理器下运行时可能不存在。对于必须在受限的安全上下文(例如Applet)中运行的代码,这是一个重要的考虑因素。
内部暴露
由于反射允许代码执行在非反射代码中是非法的操作,例如访问私有字段和方法,因此使用反射可能会导致意外的副作用,这可能会使代码无法正常工作并可能破坏可移植性。反射性代码破坏了抽象,因此可能会随着平台的升级而改变行为。
经验教训
本教程介绍了反射在访问和操作类,字段,方法和构造函数方面的常见用法。每节课均包含代码示例,技巧和故障排除信息。
Classes
本课显示了获取Class对象并使用它检查类的属性的各种方法,包括其声明和内容。
Members
本课描述如何使用反射API查找类的字段,方法和构造函数。提供了用于设置和获取字段值,调用方法以及使用特定构造函数创建对象的新实例的示例。
Arrays和枚举类型
本课介绍了两种特殊类型的类:在运行时生成的数组和定义唯一命名对象实例的枚举类型。示例代码显示了如何检索数组的组件类型以及如何设置和获取具有数组或枚举类型的字段。
注意:
本教程中的示例旨在用于尝试使用反射API。因此,异常的处理与生产代码中使用的处理不同。特别是,在生产代码中,不建议转储用户可见的堆栈跟踪。
类
每种类型都是引用或原始类型。类,枚举和数组(都继承自java.lang.Object)以及接口都是引用类型。引用类型的示例包括java.lang.String,原始类型的所有包装器类,例如java.lang.Double,接口java.io.Serializable和枚举javax.swing.SortOrder。有一组固定的原始类型:布尔值,字节,短型,整数,长型,字符,浮点型和双精度型。
对于每种类型的对象,Java虚拟机都会实例化一个不可变的java.lang.Class实例,该实例提供检查对象的运行时属性(包括其成员和类型信息)的方法。类还提供了创建新类和对象的能力。最重要的是,它是所有反射API的入口点。本课涵盖了最常见的涉及类的反射操作:
检索类对象
检查类修饰符和类型
发现类成员
故障排除
成员
Arrays和枚举类型